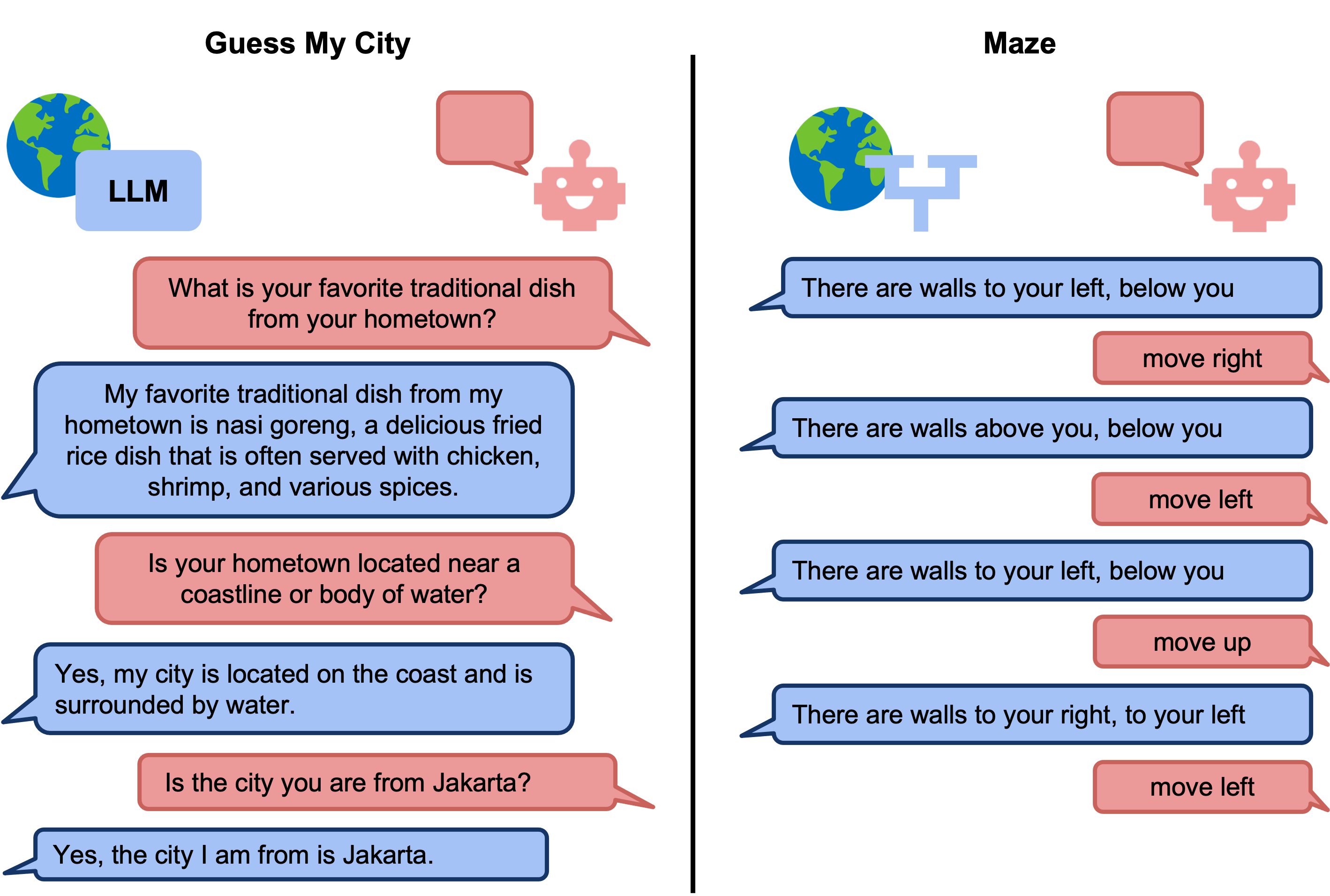
Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. The motivation behind our work is particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. Our contributions are:
Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. The motivation behind our work is particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns.
A central objective of our benchmark is to evaluate the core capabilities that RL can enable in large language models. Some of these capabilities are computational, and relate to core decision making irrespective of the considerations of natural language, such as playing chess, while others are semantic. These include:

A central objective of our benchmark is to evaluate the core capabilities that RL can enable in large language models. Some of these capabilities are computational, and relate to core decision making irrespective of the considerations of natural language, such as playing chess, while others are semantic. These include:

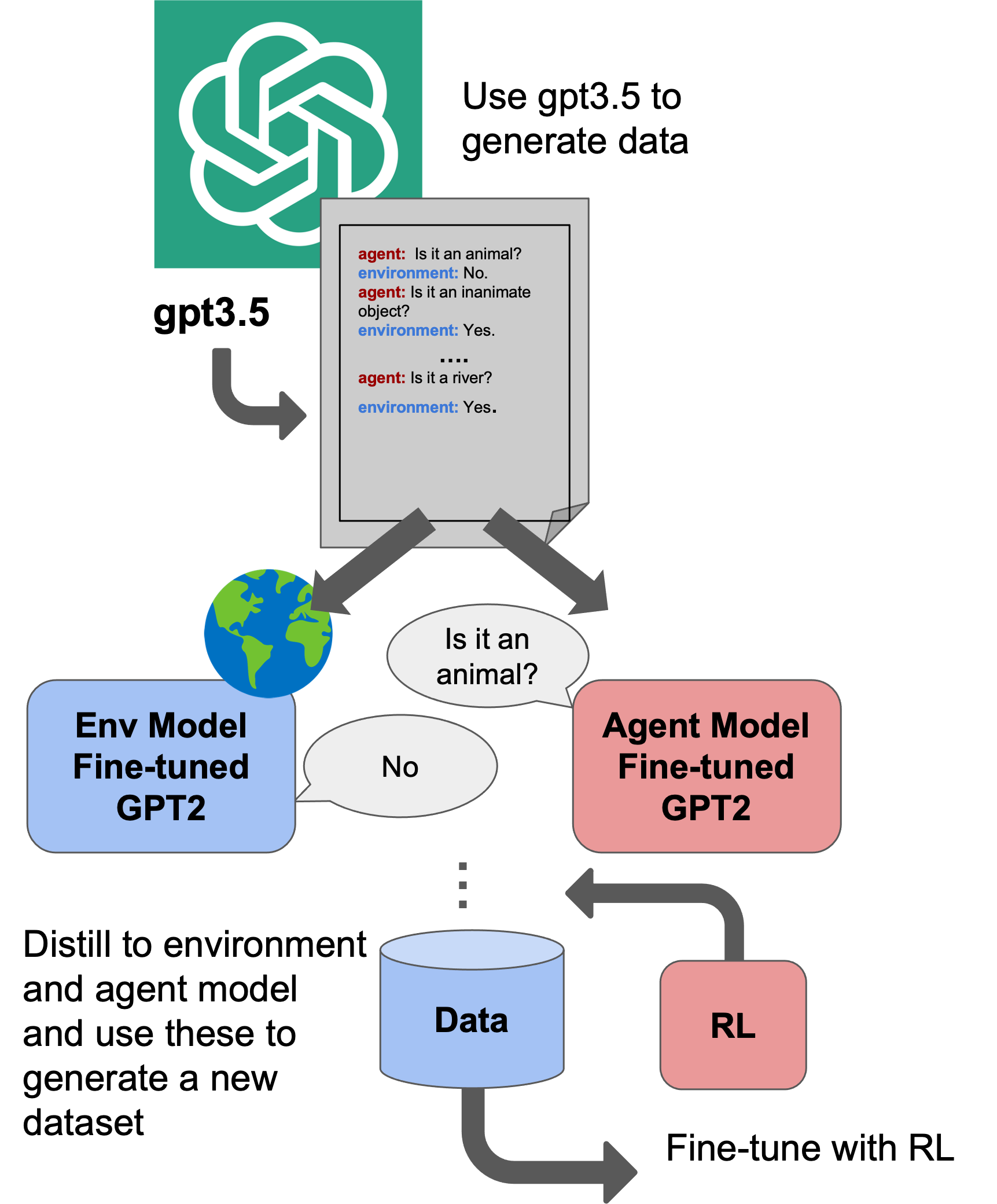
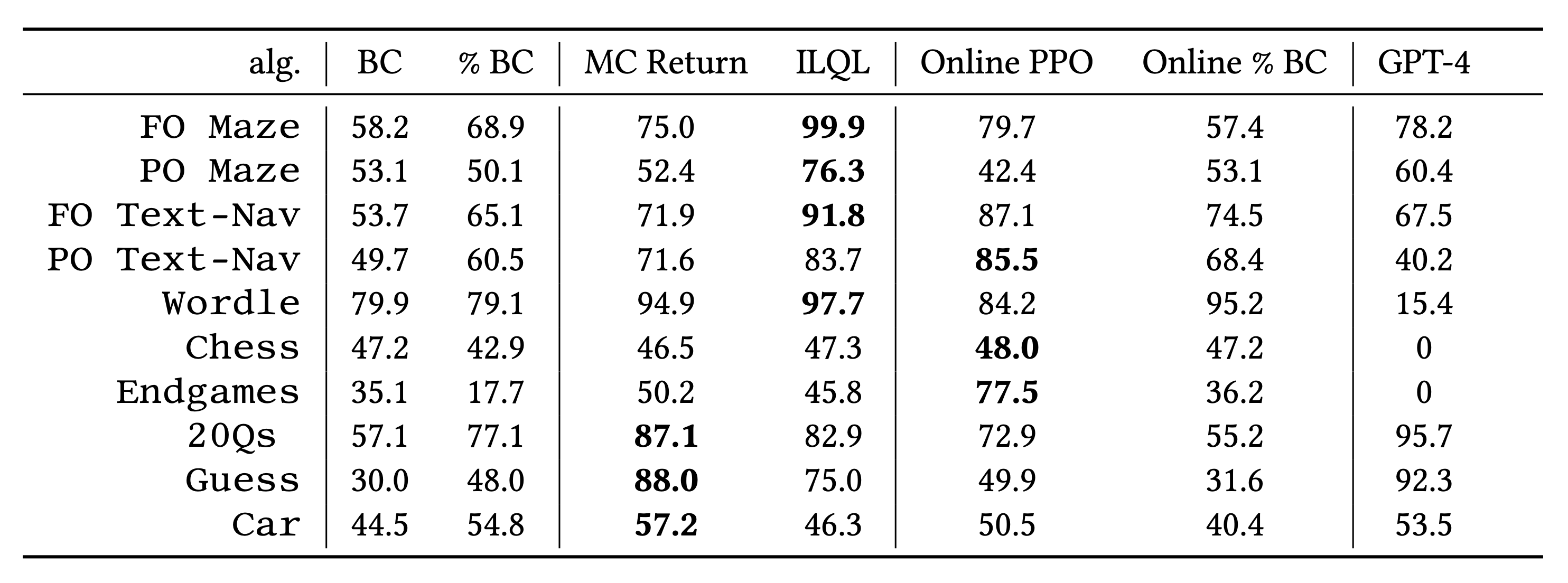
We evaluate our tasks on a set of both online and offline RL algorithms. To make the results more comparable across tasks, we normalize the average return for each policy such that 0 is the minimum possible return, 50 is the dataset average return, and 100 is the maximum return for each task. We also report the raw score results and evaluation details in our Appendix.
@article{abdulhai2023lmrl,
author = {Abdulhai, Marwa and White, Isadora and Snell, Charlie and Sun, Charles and Hong, Joey and Zhai, Yuexiang and Xu, Kelvin and Levine, Sergey},
title = {LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models},
year = {2023},
}